Document Composition
Contents
- Overview
- Translating Executable Models
- Transformation Architecture
- A Rule Based Language
- Implementation
Overview
When mapping models to code (and other structured targets) it would be nice of the structure of the target matched the structure of the source. When this happens, individual elements in the source model can be transformed into elements of the target model, and the resulting target elements are then just grouped together to form the result. For example, when translating UML model classes with attributes to Java class definitions, each UML class turns into a Java class definition, each attribute in the UML class produces a corresponding attribute in the Java class. The structure is the same, but the detail of representation is different.Unfortunately this situation does not often occur. For example, UML models consist of separate elements for classes, associations and state machines; each of these model elements are distinct, but they reference each other. A translation from UML to Java may choose to produce a single class definition consisting of:
- Java classes for UML classes;
- Java fields for UML class attributes and association role ends;
- A state field.
- An enumeration in each Java class for each UML message.
- A single Java method in a class for handling messages;
- A case for each transition within the message handler.
It is certainly possible to pass tables around the source model and build up the required parts of the target model. However, it is possible to do better than that and to use a language driven approach to hide away the details of how the target model is built up. The transformation language constructs can be pattern directed and the output can be declarative in such a way as to focus on mapping source elements to target elements without having to say too much about the mechanisms by which the output is produced.
Translating Executable Models
This section describes a typical scenario where the translation from models to program code requires the target code to pull together information from different parts of the source model. A fully executable program is produced by translating class models and state machines to Java. The example is a car cruise controller and is very simple, but is representative of a large number of strategies for producing programs from models.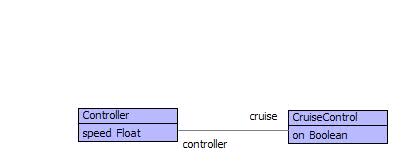
The figure above shows a simple model consisting of classes, attributes and associations. A car engine controller manages the speed of the car and communicates with the cruise control system. The cruise control system is managed via a mechanical switch on the dashboard.
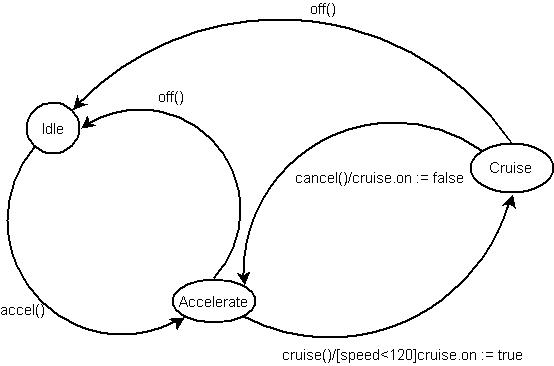
The state machine above shows the behaviour of the engine controller. The engine starts in the Idle state when it is switched on. When the controller detects the accelerator being pressed, it switches to the Accelerate state. When the car is accelerating, the driver can press the cruise control button on the dashboard causing the controller to switch to the Cruise state providing that the speed is less than a preset amount (120). In the cruising state, the driver can switch the control off by pressing the accelerator. When switching to and from the cruising state, the engine controller communicates with the cruise controller, setting its 'on' state.
Given the behavioural models defined in the above figures it is possible to produce a fully executable Java program. The program consists of class definitions for the two classes in the model. Each class includes fields, accessors, updaters and a message handling operation; the definition of these components comes from different aspects of the source model.
The rest of this section shows the program code generated from the Controller class. The example is representative of the code generated from any class in a behavioural model. Firstly, each model class produces a Java class definition (the missing definitions are given subsequently):
class Controller {
// Messages...
// Fields...
// Accessors...
// Updaters...
// Message passing...
}
// Messages...
public static final int accel = 0;
public static final int cruise = 1;
public static final int off = 2;
public static final int cancel = 3;
- Each model class defines a collection of attributes with simple types (such as String or Integer); for example the engine controller class defines an attribute 'speed' of type 'Float'.
- The model requires that each object exists in one of a given number of states; for example the engine controller has states for Idle, Cruise and Accelerate.
- The model contains a number of associations between classes. The associations allow instances of the classes to communicate with each other. The engine controller class has an association with the cruise controller class with role end names cruise and controller.
// Fields...
Float speed; // Simple attribute.
String state; // Current state.
CruiseControl cruise; // Association role end.
// Accessors and updaters...
public CruiseControl getcruise() { return cruise; }
public Float getspeed() { return speed; }
public void setcruise(CruiseControl cruise) {
this.cruise = cruise;
}
public void setspeed(Float speed) {
this.speed = speed;
}
public void send(int message,Object[] args) {
switch(message) {
// Transitions...
}
}
case m:
// Transition...
if(state == s && g) {
a;
state = t;
}
break;
// Message passing...
public void send(int message,Object[] args) {
switch(message) {
case Controller.accel:
if(state.equals("Idle"))
state = "Accelerate";
break;
case Controller.cruise:
if(state.equals("Accelerate") && speed < 120)
cruise.seton(true);
state = "Cruise";
break;
case Controller.off:
if(state.equals("Accelerate"))
state = "Idle";
break;
case Controller.cancel:
if(state.equals("Cruise"))
cruise.seton(false);
state = "Accelerate";
break;
case Controller.off:
if(state.equals("Cruise"))
state = "Idle";
break;
default: throw new Error("No message " + message);
}
Transformation Architecture
Before looking at a language that supports the generation of code for models, it is worth considering the steps taken by a mechanical process. The idea is that the mechanical process is driven by code generation rules and that the rules encode any domain specific information about the models being transformed. The code generation rules are pattern directed and follow the structure of the source model:for each class c
emit a Java class definition.
emit a state field.
for each attribute a of c
emit a field definition for a.
emit an access and updater for a.
emit a message handling method.
for each association A
emit a field for end1
emit a field for end2
for each state machine m for class c
for each transition t of m
emit a constant field to c for message(t)
emit a message case for t to c
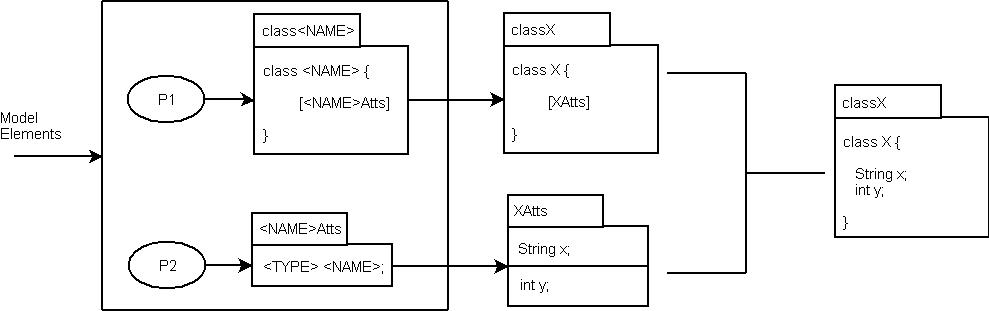
An overview of the architecture of the transformation process shown above. Model elements are supplied to the rules in the rule base. Each rule consists of a source pattern and a target pattern. Two rules are shown:
- R1: Pattern P1 matches a class in the model. The output pattern describes a Java class labelled with the class name.
- R2: Pattern P2 matches an attribute in the model. The output pattern describes a Java field labelled with the name of the owning class.
The figureshows three document templates produced from the rule-base. The first is labelled with classX and is the result of mapping a model class named X to a Java class. The second and third are both labelled with XAtts and are the result of mapping two class attributes named x and y to Java fields. The classX template contains a reference to a label XAtts that is a placeholder for the fields of the class.
A document template is transformed into a document by replacing all label references with documents. This process is called displaying the document template. The display process is shown as the final step where the occurrence of XAtts in the class definition is replaced with all the field definitions labelled XAtts.
Rule firing may involve multiple passes over the data; the output pattern of each rule may refer to other rule-bases (including its own) and supply data to those rule-bases to produce the final document templates. For example, the rule R1 is supplied with a class, emits a document template for the class but also calls the rule-base again with the attributes of the class so that rule R2 fires on each attribute. All rule firing is completed before document display takes place.
A Rule Based Language
The transformation from a model to code is performed by a rule-base containing a collection of rules. The rule base is supplied with one or more model elements as input. It tries the rules in turn until one of the rules matches the input. The body of the matching rule is forced to produce a document template. The template may be labelled and may contain labelled placeholders. The rule-base may be performed multiple times against different model elements. Once execution is complete, the templates are displayed by matching placeholder labels against labelled output. The result is an output document with no unresolved labels that can be displayed as text. This section describes the features of the rule-base language and concludes with the complete behavioural modelling rule-base as described in the previous section.A rule-base with the name N has the following format:
@RuleBase N
// Rules...
end
@Rule R P1,P2,...,Pn ->
D1 D2 ... Dm
end
Here is a simple example of a rule:
@Rule Anything x ->
<x>
end
A pattern may match an object:
@Rule ToJava Class[name=n] ->
"public class " + <n> + "{"
end
public class Element {
@Rule ToJava Class[name=n] ->
"public class " + <n> + "{" +
->[ nl +
"public String state;"
] + nl +
"}"
end
public class Element {
public String state;
}
@Rule ToJava Class[name=n,attributes=A] ->
"public class " + <n> + "{" +
->[ nl +
"public String state;" + nl
{ <A> <map> nl empty }
] + nl +
"}"
end
The collection component S may be a label or an expression. In the example above <A> is an expression where A is provided by the context of the rule firing. The mapping component M is an expression. The variable map always refers to the containing rule-base and therefore allows the rule base to be applied as part of a rule firing. The combiner nl causes the documents to be combined by joining them together with newlines. The document empty is just that. Note that nl and empty are builtin so we don't put < and > round them.
Suppose that C is a class with two attributes x and y of type String and Integer respectively. Using the above definition to transform C produces the following (assuming suitable rule definitions for attribute to field transformation):
public class C {
public String state;
String x;
int y;
}
@Rule MapStrAtt
Attribute[name=n,type=NamedElement[name="String"]] ->
"String " + <n> + ";"
end
@Rule MapIntAtt
Attribute[name=n,type=NamedElement[name="Integer"]] ->
"int " + <n> + ";"
end
// More cases...
@Rule ToJava Class[name=n,attributes=A] ->
"public class " + <n> + "{" +
->[ nl +
"public String state;" + nl
{ [n + "Atts"] <@Operation(a) map(a,n) end> nl empty }
] + nl +
"}"
end
@Rule MapStrAtt
Attribute[name=n,type=NamedElement[name="String"]],
className ->
emit[className + "Atts"]
"String " + <n> + ";"
end
This concludes the overview of the rule language for transforming model elements. The key features of element patterns are: constants; variables; object patterns with slots. The key features of the document patterns are: literal strings; delayed expressions in < ... >; combination with +; indentation and newlines with ->[ ... ] and nl; labels with [ ... ]; tagged documents using 'emit'; combining collections with { ...}.
Finally, the rules for the Java mapping are defined below. There are two rule bases. The first is used to map model types to Java types and the second is used to map packages, classes, attributes and state machines to Java classes. The first rule base is defined in its entirety below and the second is defined on a rule-by-rule basis.
Model types are named elements. The names must be mapped to the appropriate Java types. To simplify the example, sets and sequences are translated to vectors:
@RuleBase Types
@Rule String NamedElement[name='String'] ->
"String"
end
@Rule Integer NamedElement[name='Integer'] ->
"int"
end
@Rule Integer NamedElement[name='Boolean'] ->
"boolean"
end
@Rule Sequence Seq[elementType=t] ->
"Vector<" + <map(t)> + ">"
end
@Rule Set Set[elementType=t] ->
"Vector<" + <map(t)> + ">"
end
@Rule Default NamedElement[name=n] ->
<n>
end
@Rule TranslatePackage
Package[name=n,classes=C,associations=A,packages=P] ->
emit["Package-" + n]
{ <C> <map> nl empty } +
{ <A> <map> nl empty } +
{ <P> <map> nl empty }
end
@Rule TranslateClass
Class[name=n,attributes=A] ->
// Emit a labelled class definition...
emit["Class-" + n]
"class " + <n> + " {" +
// Indent the body of the definition...
->[ nl +
// Transitions define messages,
// each message defines a constant...
{ [n + "transitions"] id nl empty } + nl +
// Each attribute defines a simple-typed Java field...
{ <A> < @Operation(a) map(a,n) end> nl empty } + nl +
// Each instance has its own state...
"String state;" + nl +
// Attributes are defined by associations...
{ [n + "attributes"] id nl empty } + nl +
// Accessors and updaters are defined elsewhere...
{ [n + "accessors"] id nl empty } + nl +
{ [n + "updaters"] id nl empty } + nl +
// Each class has a message handler...
"public void send(int message,Object[] args) {" +
// Indent the body of the method...
->[ nl +
"switch(message) {" +
// Indent the body of the switch
->[ nl +
// Each transition produces a message case...
{ [n + "messages"] id nl empty } + nl +
// In case the message is not handled...
"default: throw new Error(\"No message \" + message);"
] + nl +
"}"
]
] + nl +
"}"
end
@Rule TranslateAttribute Attribute[name=n,type=t],c ->
// Produce an accessor method for this field...
emit[c + "accessors"]
<Types.apply(t)> + " get" + <n> + "()" +
"{ return " + <n> + "; }"
// Produce an updater method for this field...
emit[c + "updaters"]
"void set" + <n> + "(" + <Types.apply(t)> + " " + <n> + ")" +
"{ this." + <n> + " = " + <n> + "; }"
// Produce the field definition...
<Types.apply(t)> + " " + <n> + ";"
end
@Rule TranslateAssociation Association[end1=e1,end2=e2] ->
// Produce definitions for the class at end1...
<map(e1,e2)>
// Produce definitions for the class at end2...
<map(e2,e1)>
// Just for side effect...
empty
end
@Rule TranslateEnd
End[name=n1,type=t1],End[name=n2,type=t2] ->
// produce a field definition for the class t1...
emit[t1.name() + "attributes"]
<Types.apply(t2)> + " " + <n2> + ";"
// Produce an accessor method for t1...
emit[t1.name() + "accessors"]
"public " + <Types.apply(t2)> + " get" + <n2> + "() { " +
->[ nl +
"return " + <n2> + ";" + nl
] + nl + "}"
// produce an updater for t1...
emit[t1.name() + "updaters"]
"public void set" + <n2> +
"(" + <Types.apply(t2)> + " " + <n2> + ") { " +
->[ nl +
"this." + <n2> + " = " + <n2> + ";" + nl
] + nl + "}"
end
@Rule TranslateMachine StateMachine[class=c,states=S,trans=T] ->
// Translate the messages to constants. Use ->asSet
// to remove duplicate message names...
<map(T.message->asSet->asSeq,T.message->asSet->asSeq,c)>
// translate the transitions to message handling cases...
<map(T,c)>
end
@Rule TranslateMessages allMessages,Seq{message|messages},class ->
// Produce a constant (use the position
// of the name as its value)...
<map(message,class,allMessages->indexOf(message))>
// Map the rest of the messages...
<map(allMessages,messages,class)>
end
@Rule NoMessagesLeft allMessages,Seq{},class ->
// No messages, requires no constants...
empty
end
@Rule TranslateMessage message,Class[name=className],index ->
// Produce a constant with value index...
emit[className + "transitions"]
"public static int " + <message> + " = " + <index> + ";"
end
@Rule TranslateTrans Seq{
Trans[source=s, // Source state name
target=t, // Target state name
message=m, // Message name
condition=p, // Condition (Java code)
action=a // Action (Java code)
] | T}, // T is more transitions
c -> // Class that owns the transition
// Produce a case definition for the message handling
// method for class c...
emit[c.name() + "messages"]
// This case handles the message m...
"case " + <c.name()> + "." + <m> + ":" +
->[ nl +
// check we are in the appropriate state s and
// the predicate p is true...
"if(state.equals(" + <str(s)> + ") && " + <p> + ")" +
->[ nl +
// Perform the action...
<a> + ";" + nl +
// Change to the target state...
"state = " + <str(t)> + ";"
// Break out of the switch...
] + nl + "break;"
]
// Translate the rest of the transitions...
<map(T,c)>
end
@Rule TranslateNoTrans Seq{},c ->
// The base case...
empty
end
Implementation
The previous section has defined the syntax of a language for pattern directed document generation rules. The language addresses the code generation composition problem whereby the structure of the input model elements does not match the structure of the output code. Labels are used to tag the generated code (or document templates) and to define placeholders that are then resolved in a subsequent phase.This section defines the rule-based document generation language. There are several parts to the definition: the language of patterns, the language of documents and the label resolution mechanism. Each of these are explained in turn.
Implementation 1: Pattern Matching
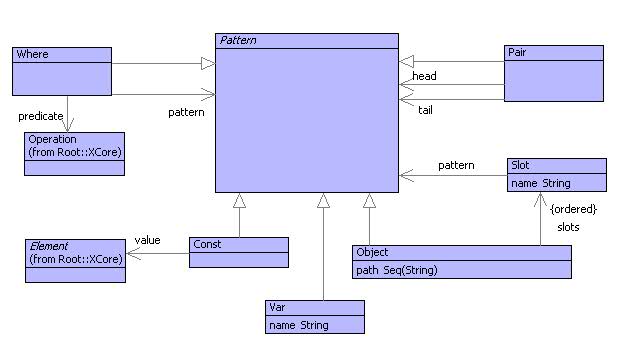
The figure above shows the definition of a pattern language. Patterns occur frequently in language definitions where it is useful to extract elements from data depending on the structure of the data. When this is a requirement is it almost always cost effective to define a pattern language and a pattern matching mechanism that it is to write the corresponding program code that extracts the elements each time they are required. For example, the pattern:
C[x=10,y=v]
if element.isKindOf(C)
then
if element.x = 10
then // bind "v" to 10
else // fail match
end
else // fail match
end
The simplified grammar for patterns is shown below:
@Grammar
Constant ::=
s = Str { Const(s) }
| i = Int { Const(i) }
| 'true' { Const(true) }
| 'false' { Const(false) }.
EmptySeq ::= '}' { Const(Seq{}) }.
HeadTail ::= h = Pattern '|' t = Pattern '}' { Pair(h,t) }.
Pair ::= 'Seq{' (HeadTail | EmptySeq).
Path ::= p = ('::' Name)* { p }.
Pattern ::=
Constant
| n = Name NameTail^(n)
| Pair.
NameTail(n) ::=
p = Path '[' s = Slots ']' { Object(Seq{n|p},s) }
| { Var(n) }.
Slots ::=
s = Slot ss = (',' Slot)* { Seq{s | ss} }
| { Seq{} }.
Slot ::= n = Name '=' p = Pattern { Slot(n,p) }.
end
C[x=10,y=v]
context Const
@Operation match(value,env)
if value = self.value
then env
else null
end
end
context Var
@Operation match(value,env)
env->bind(name,value)
end
context Pair
@Operation match(value,env)
if value.isReallyKindOf(Seq(Element)) and
not value = Seq{}
then
env := head.match(value->head,env);
if env <> null
then tail.match(value->tail,env)
else env
end
else null
end
end
context Object
@Operation match(value,env)
if value.isReallyKindOf(self.classifier())
then
@For slot in slots do
if env <> null
then env := slot.match(value,env)
end
end;
env
else null
end
end
context Slot
@Operation match(object,env)
if object.hasSlot(name)
then pattern.match(object.get(name),env)
else null
end
end
Implementation 2: Documents
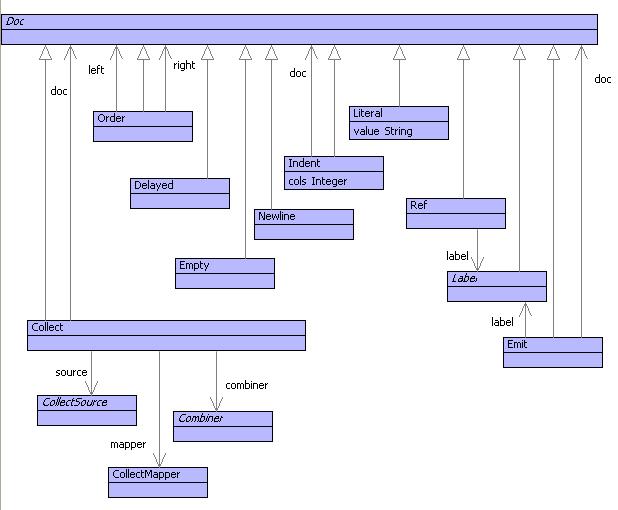
The model is used in three ways: to represent document patterns in rules; to represent document templates; to represent document displays. The difference between these three uses is: patterns may contain delayed expressions; templates may contain unresolved labels; document displays contain no unresolved labels and no delayed expressions.
The classes in the model match the constructs in the language examples from the previous section. The following classes are worth noting: the source, mapper and combiner of a collect are classes that are specialized in specific ways for different kinds of builtin collection operations; Label is a class that is either specialized as a delayed label or a literal label.
Delayed document components are used to allow arbitrary expressions to be embedded. The expressions are to be evaluated when the document is created in the context of the environment produced by successful pattern matching. When the delayed document is created, the expression is turned into an operation whose arguments correspond to the variable names used in the expression. Delayed components include: source, mapper and combiner of a collect; a delayed document; and a delayed label.
The grammar for documents is shown below:
@Grammar extends OCL::OCL.grammar
Doc(FV) ::= d = AtomicDoc^(FV) DocTail^(FV,d).
AtomicDoc(FV) ::=
Build^(FV)
| Delayed^(FV)
| Emit^(FV)
| Empty
| Newline
| Ref^(FV)
| Literal
| Indent^(FV)
| Label^(FV).
DocTail(FV,d1) ::=
'+' d2 = Doc^(FV) { Order(d1,d2) }
| { d1 }.
Build(FV) ::=
'{' s = Source^(FV)
m = Map^(FV)
c = Combiner d = Doc^(FV)
'}' {
Collect(s,m,c,d)
}.
Source(FV) ::=
LabelSource^(FV)
| DelayedSource^(FV).
LabelSource(FV) ::= '[' e = Exp ']' op = DocOp^(FV,e) {
DelayedLabelSource(op)
}.
Map(FV) ::=
'<' e = DelayedExp '>' op = DocOp^(FV,e) {
DelayedMapper(op) }
| 'id' { IdMap() }.
DelayedSource(FV) ::= '<' e = Exp '>' op = DocOp^(FV,e) {
DelayedSource(op)
}.
Combiner ::=
'nl' { CombineWithNewlines() }
| 'ignore' { Ignore() }.
Label(FV) ::= '[' e = Exp ']' op = DocOp^(FV,e) {
DelayedLabel(op)
}.
Delayed(FV) ::= '<' e = Exp '>' op = DocOp^(FV,e) {
Delayed(op)
}.
Emit(FV) ::= 'emit' l = Label^(FV) d = Doc^(FV) {
Emit(l,d)
}.
Empty ::= 'empty' { Empty() }.
Newline ::= 'nl' { Newline() }.
Ref(FV) ::= '!' l = Label^(FV) { Ref(l) }.
Literal ::= s = Str { Literal(s) }.
Indent(FV) ::= '->' '[' d = Doc^(FV) ']' {
Indent(2,d)
}.
DocOp(FV,e) ::= { DocOp(FV,e) }.
end
@Rule Class[name=n] -> "class " + <toUpper(n)> end
@Operation(n) toUpper(n) end
The rest of the Doc grammar should be self explanatory. Note that some classes are used that are not shown in the document model above. These are sub-classes of Label and collection classes; they capture various special cases and associate them with special purpose syntax.
Implementation 3: Rules and Rule Bases
The figure below shows the model of rules and rule bases: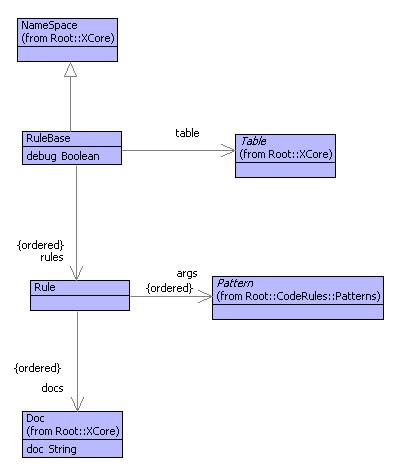
A rule consists of a sequence of patterns and a sequence of documents. A rule base is a sequence of rules that will be tried in turn when the rule base is supplied with elements. A rule base has a table that is used to hold associations between labels and documents when rules are fired. On the resolution pass, labels are replaced with their documents from the table. The table also allows particular documents to be indexed by their name; for example only part of a document in a large model can be re-generated.
The rest of this section describes how rules are fired and then the resulting document is produced by resolving labels. Argument elements are supplied to a rule base via the operation apply defined below.
Each rule is applied to the args in turn until one is enabled by returning a non-null environment. When this occurs the rule is fired, supplying the environment to the rule. Notice that the environment is extended with a binding for 'map' which allows the document to call the rule-base again:
context RuleBase
@Operation apply(args)
let done = false;
result = null
in @For rule in R when not done do
let env = rule.match(args,Seq{})
in if env <> null
then
let env = env->bind("map",
@Operation(.args)
self.apply(args)
end)
in done := true;
result := rule.fire(env,table)
end
end
end
end;
if not done
then self.error(formats("No rule for (~{,~;~S~}~%",Seq{args}))
else result
end
end
end
context Rule
@Operation match(values,env)
if args->size = values->size
then
@For arg,value in args,values do
if env <> null
then env := arg.match(value,env)
end
end;
env
else null
end
end
Implementation 4: Forcing Delayed Documents
context Rule
@Operation fire(env,table)
let result = null
in @For doc in docs do
result := doc.force(env,table)
end;
result
end
end
- Components of a document may be delayed expressions that evaluate to produce documents. These include expressions in < .. > and within the [ ... ] part of emit and label references. Forcing a document evaluates the delayed expressions and returns the original document with the delayed expressions replaced with the results.
- Components of a document may be 'emit'-ed. Forcing a document updates the document table with associations between the emit-label and the emit-document (after delayed expressions have been evaluated).
context Collect
@Operation force(env,table)
// Just return the collect with the
// components forced...
Collect(
source.force(env),
mapper.force(env),
combiner,
doc.force(env,table))
end
context Delayed
@Operation force(env,table)
// Get the bindings from the environment that provide values
// for the parameter names of the operation...
let args = operation.paramNames()
->collect(name |
env->lookup(name.toString())) then
// Force the delayed expression by supplying the argument
// values...
value = operation.invoke(self,args)
in // Coerce the return value to be a document...
@TypeCase(value)
Doc do
value
end
else Literal(value.toString())
end
end
end
context Emit
@Operation force(env,table)
// Force the label...
let label = label.force(env) then
name = label.label();
// Force the body...
doc = doc.force(env,table)
in // Extend the table with an entry for the label...
if table.hasKey(name)
then table.put(name,table.get(name) + Seq{doc})
else table.put(name,Seq{doc})
end;
doc
end
end
Implementation 5: Displaying Documents
Once rules have been fired and all documents have been forced, the result is a table that associates labels with document templates. A document template may contain label references; it is translated to a document by replacing all the references. This is done using the display operation of the rule base as shown below:@Operation display(label:String)
// Display the document with the given label...
if table.hasKey(label)
then
// Use a string output buffer because there may be
// lots of output...
let buffer = Buffer(1000,true)
in table.get(label)->at(0).display(0,table,buffer);
buffer.toString()
end
else self.error("No label in table: " + label)
end
end
The Collect class expects the collect source to produce a sequence of documents, each of which is mapped and then combined to produce a final single document that is displayed:
@Operation display(indent,table,buffer)
source.elements(table)->iterate(element doc = doc |
combiner.combine(doc,mapper.map(element)))
.display(indent,table,buffer)
end
@Operation display(indent,table,buffer)
if table.hasKey(label)
then table.get(label)->at(0).display(indent,table,buffer)
else self.error("Label: cannot find label " + label)
end
end
@Operation display(indent,table,buffer)
buffer.add("\n"->at(0));
buffer.append(formats("~V",Seq{indent}))
end
@Operation display(indent,table,buffer)
left.display(indent,table,buffer);
right.display(indent,table,buffer)
end