Databases
Contents
Overview
Simple Records
This section provides an introduction to the definition of language construct. All aspects of a new construct are covered, but the construct is rather simple since it supports data records consisting of fields with names and values. The record construct is an example of an integrated language construct since the field values can be any language construct supported by XOCL. Since XOCL is itself open-ended, this allows record field values to be expressed as any language construct including records and those constructs we have not even thought of yet!Our requirement is for a database containing records. Each record has a collection of fields with a name and a value. A database may be filtered by supplying it with a predicate that expects a record. The result is a new database containing all those fields that satisfied the predicate.
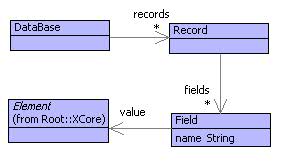
It is usual to start off with a data definition for the elements that are required. Figure shows the contents of a package called Records. A database consists of a set of records. Each record is a set of fields. Each field has a value that can be of any data type (since Element is the super-class of everything).
The next step is to define a concrete syntax for the Record construct that will synthesize an expresstion whose evaluation produces an instance of the class Record. The complete grammar for Record is defined below, followed by a step-by-step description:
context Record
@Grammar extends OCL::OCL.grammar
Record ::= r = { [| Record() |] } Fields^(r) 'end'.
Fields(r) ::= r = Field^(r) FieldTail^(r) | { r }.
Field(r) ::= n = Name '=' e = Exp {
[| <r>.addToFields(Field(<n.lift()>,<e>)) |]
}.
FieldTail(r) ::= ',' Fields^(r) | { r }.
end
The rule named Record defined above, creates an expression named r that will create a new record when evaluated. The expression r is passed as an argument to the rule named Fields. Once fields has completed its parse, the keyword 'end' is expected. If successful, the value returned by Fields is the result of the parse. So far we have dealt with the following concrete syntax:
@Record
???
end
A field is defined by the rule Field, it is a name n, followed by = followed by an expression e. If successful, it synthesizes an expression that adds a field to the supplied record r. So far, the following can be recognized:
@Record
name = "Fred"
end
The grammar is complete and the following records can be recognized and the appropriate expressions synthesized:
@Record
name = "Fred",
age = 35
end
Record()
.addToFields(Field("name","Fred"))
.addToFields(Field("age",35))
Trees
Information often naturally forms a tree structure where each component of information is related to several children. Think of company structures: responsibilities from CEO downwards or groupings from the board down. Trees are often used to model physical entities such as cars where a car consists of a body, an engine, electrical system, interior etc. and where a body consists of doors, a windscreen etc.Trees are useful when we want to organise a model in terms of parent-child relationships which may be physical containment or may be logical groupings (think of nested sets). This section gives an example of a language for expressing trees for classification.
Consider a collection of bank records that are to be classified with respect to awarding a loan. The first step to awarding the loan is to determine an income threshold. If the applicant does not have an annual salary of four times the loan amount then the loan is denied.
The next step is to consider the current debt position of the applicant. If the applicant has debts of more than £10K then the loan is denied. If they have debts of £5 - £10K then the loan application is referred otherwise the application might be awarded.
Finally, if the applicant has an account with the bank, then the loan is awarded otherwise it is referred.
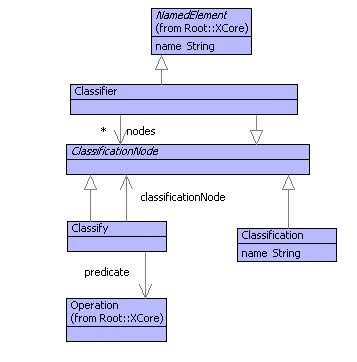
Figure shows a simple model of a classification tree. A classifier is a named element (so that it can be put in name spaces and then referred to from elsewhere). A classification is a property of some data (for example Award the loan, Deny the loan or Refer the loan). Finally, a classify, is something that applies a predicate to some data to determine whether the classification given by the classificationNode applies.
To construct a classification tree, proceed as follows. Start with a classifier node. Its child nodes, will be classify nodes with disjoint predicates. The child node of a classifier node will be either a classification or another classifier. Proceed with the tree until all categories are classified.
The following example shows a classifier for a loan:
@Operation loan(bank,amount)
@Classifier Loan
@Classify(applicant)
applicant.lookup("salary") * 4 > amount
@Classifier
@Classify(applicant)
applicant.lookup("debt") >= 10000
@Classification Deny end
end
@Classify(applicant)
applicant.lookup("debt") < 10000 and
applicant.lookup("debt") >= 5000
@Classification Refer end
end
@Classify(applicant)
applicant.lookup("debt") < 5000
@Classifier
@Classify(applicant)
applicant.lookup("bank") = bank
@Classification Award end
end
@Classify(applicant)
applicant.lookup("bank") <> bank
@Classification Refer end
end
end
end
end
end
@Classify(applicant)
applicant.lookup("salary") * 4 <= amount
@Classification Deny end
end
end
end
The operation loan may be applied to any number of banks and loan amounts. In each case it returns a different classifier.
The classification language is defined by adding a grammar to each of the appropriate classes in the classification model. Each class gets its own grammar so that the classification language is not fixed. The classification language is integrated into XOCL and the components of the language are extensible (new types of classifier node can be defined later and they can be integrated with no changes to the existing components).
Classification is the simplest grammar:
@Grammar
Classification ::= n = Name 'end' {
[| Classification(<n.lift()>) |]
}.
end
@Grammar extends OCL::OCL.grammar
Classify ::= '(' n = Name ')' e = Exp c = Exp 'end' {
[| Classify(@Operation(<n>) <e> end,<c>) |]
}.
end
Classification involves sequences of XOCL expressions (an arbitrary number of child classification nodes); it is defined as follows:
@Grammar extends OCL::OCL.grammar
Classifier ::= n = OptName c = Classifications 'end' {
[| Classifier(<n.lift()>,<c>) |]
}.
Classifications ::= e = Exp cs = Classifications {
[| <cs> ->including(<e>) |]
} | { [| Set{} |] }.
OptName ::= Name | { "anon" }.
end
Collections and Comprehensions
It is usual for data to form collections: employees; customer transactions; connected clients. When modelling collections of data it is very convenient to have language structures that make it easy to create, transform and filter the collections. This section describes how such a language construct can be defined.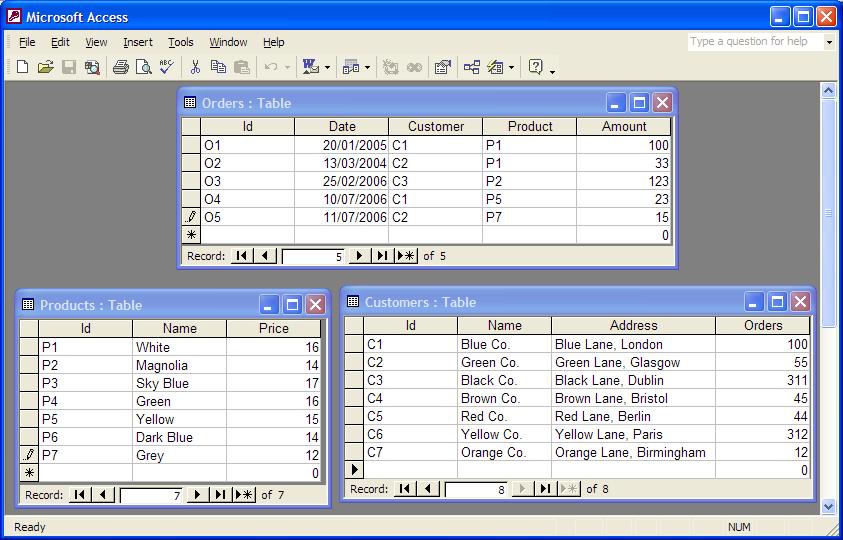
The Products table shows all the types of paint that the company sells along with the current price per unit. Finally, the Orders table shows the orders that have been placed, linking customers, products and amount.
Database tables contain records expressed as rows. Each table is modelled as a class and the records modelled as instances of the class grouped together as a set. The diagam in figure shows three classes corresponding to the three database tables above.
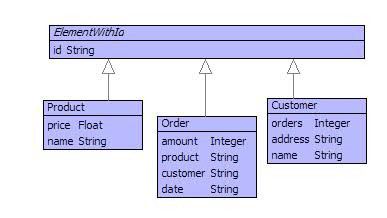
The model above has chosen to represent the database tables directly: each table uses the id field as a primary key and each class has modelled this directly. Unlike database records, objects have a unique identity, so this is not strictly necessary. It is useful to retain the id field to show how database style queries and operations are supported by the collection language construct below.
The database records are modelled as instances of the classes as shown below:
Root::Customers := Set{
Customer("C1","Blue Co.","Blue Lane, London",100),
Customer("C2","Green Co.","Green Lane, Glasgow",55),
Customer("C3","Black Co.","Black Lane, Dublin",311),
Customer("C4","Brown Co.","Brown Lane, Bristol",45),
Customer("C5","Red Co.","Red Lane, Berlin",44),
Customer("C6","Yellow Co.","Yellow Lane, Paris",312),
Customer("C7","Orange Co.","Orange Lane, Birmingham",122)
};
Root::Products := Set{
Product("P1","White",16),
Product("P2","Magnolia",14),
Product("P3","Sky Blue",17),
Product("P4","Green",16),
Product("P5","Yellow",15),
Product("P6","Dark Blue",14),
Product("P7","Grey",12)
};
Root::Orders := Set{
Order("O1","20/01/2005","C1","P1",100),
Order("O2","13/03/2004","C2","P1",33),
Order("O3","25/25/2006","C3","P2",123),
Order("O4","10/07/2006","C1","P5",23),
Order("O5","11/07/2006","C2","P7",15)
};
@Operation newId(E:Set(ElementWithId)):String
let i = 0
in @While (not E->isEmpty) and
(not E->exists(e | e.id = "X" + i)) do
i := i + 1
end;
i
end
end
@Operation addCustomer(name:String,address:String)
let id = newId(Customers) then
newCustomer = Customer(id,name,address,0)
in Root::Customers := Customers->including(newCustomer)
end
end
A query on one or more database tables involves performing a test on each of the records in the table and producing a new table as a result. In the model, a table is represented as a collection of elements. The new language construct Cmp (short for comprehension) allows us to do a query as follows:
(1) @Operation ordersGreaterThan(x:Integer):Seq(Customer)
(2) @Cmp customer where
(3) customer <- Customers,
(4) ? customer.orders > x
end
end
A Cmp expression has the following general form:
@Cmp body where clauses end
Consider the definition of ordersGreaterThan again. Line (3) causes each sucessive customer to be selected from the Customers table. Line 4 allows only those customers to proceed whose orders value passes the test. Finally, a sequence is returned containing all those customers (2) that get through the test.
The following is an example of a query that involves multiple binding and filters:
@Operation customersWhoBuy(product:String):Seq(String)
@Cmp c.name where
c <- Customers,
o <- Orders,
p <- Products,
? p.name = product,
? o.customer = c.id,
? o.product = p.id
end
end
A typical operation that occurs in a database is a join where two different tables are joined on two fields with the same value. The records that have been defined so far have ben instances of specific classes. A join does not necessary produce a record with a meaningful type (although it might); section defines a language construct for representing arbitrary records. The following expression performs a join on the three tables producing a new table of records showing the amount of each product for each customer:
@Cmp
@Record
customerName = c.name,
productName = p.name,
amount = o.amount
end
where
c <- Customers,
p <- Products,
o <- Orders,
? o.customer = c.id,
? o.product = p.id
end
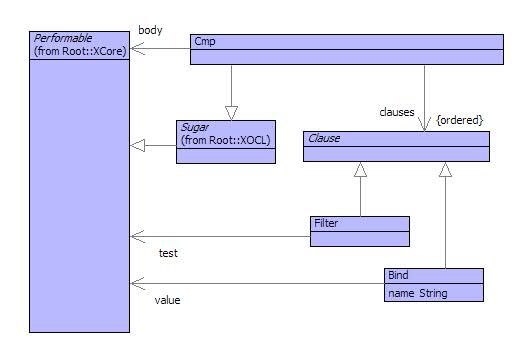
A Cmp expression is defined in terms of a package of syntax classes shown in figure . The class Cmp is defined as sugar which means that it must define an operation called desugar that turns an instance of Cmp into a Performable thing (usually an instance of OCL classes).
A Cmp has a performable body and a sequence of clauses. Each clause is either a binding or a filer. A Cmp is desugared as follows:
@Operation desugar()
@Case self of
(1) Cmp(body,Seq{}) do
[| Seq{<body>} |]
end
(2) Cmp(body,Seq{Bind(n,v)}) do
[| <v> ->asSeq ->collect(<n> | <body>) |]
end
(3) Cmp(body,Seq{Bind(n,v)|clauses}) do
[| <Cmp(Cmp(body,clauses),Seq{Bind(n,v)})>.flatten() |]
end
(4) Cmp(body,Seq{Filter(e)|clauses}) do
[| if <e> then <Cmp(body,clauses)> else Seq{} end |]
end
end
end
Case (3) occurs when there is a binding and some clauses. In this case the following equivalence is used:
@Cmp b where @Cmp
x <- S, is equivalent to @Cmp b where Cs end
Cs where
end x <- S
end->flatten
Finally, the Cmp expression has a grammar that synthesizes an instance of Cmp that, since it is an instance of Sugar, calls desugar automatically:
@Grammar extends OCL::OCL.grammar
Cmp ::= body = Exp cs = Clauses 'end' { Cmp(body,cs) }.
Clauses ::= Where | { Seq{} }.
Clause ::= Bind | Filter.
Bind ::= n = Name '<-' e = Exp { Bind(n,e) }.
Filter ::= '?' e = Exp { Filter(e) }.
Where ::= 'where' c = Clause cs = (',' Clause)* { Seq{c|cs} }
end
Transforming Comprehensions
The previous section has shown how a comprehension expression can be transformed into an XOCL expression, thereby enriching XOCL with a new language construct. Comprehensions have often been proposed as a construct suitable for performing database queries since they abstract away from the details of how the queries are performed and how the result sets are built up.A comprehension can be viewed as a query over a database if the tables are viewed as sets of records. In this way the queries are performed by selecting records, filtering them with predicates and joining them back together. However, whilst this is an attractive way to construct database queries, it does not solve the problems of how the queries are performed and how the comprehensions can be embedded into a standard programming language.
This section sketches out how comprehensions can be viewed as database queries by showing how to desugar a comprehension into a standard imperative language that provides a database interface. The translation is deliberately simple; once it has been described the conclusion outlines how the translation can be made more realistic.
Instead of the Cmp::desugar operation defined in the previous section, a new operation is defined. The operation is called toSQL and takes two arguments: the an expression to be transformed into an imperative program and a variable. At run-time, the variable will be bound to a set of values; after performing the comprehension program, the set will contain the result.
The toSQL operation proceeds by case analysis on the expression, each case is addressed in turn. The first case deals with the aituation where there are no qualifiers:
@Operation toSQL(cmp,var)
@Case cmp of
Cmp(body,Seq{}) do
[| let S = Set{}
in <toSQL(body,[| S |])>;
<var> := <var> ->including(S)
end |]
end
Cmp(body,Seq{Filter(p)}) do
[| if <p>
then <self.toSQL(Cmp(body,Seq{}),var)>
else <var> := <var> ->including(Set{})
end |]
end
Cmp(body,Seq{q|qs}) do
[| <self.toSQL(Cmp(Cmp(body,qs),Seq{q}),var)>;
<var> := <var> ->flatten;
<var>
|]
end
Cmp(body,Seq{Bind(name,OCL::Var(tableName))}) do
[| let S = DB.SQL("SELECT * FROM " + <tableName.lift()>);
P = Set{}
in @For <name> in S do
<self.toSQL(body,[| P |])>
end;
<var> := <var> ->including(P)
end |]
end
end
let S = DB.SQL("SELECT * FROM " + "V");
P = Set{}
in @For x in S do
let S = DB.SQL("SELECT * FROM " + "W");
P = Set{}
in @For y in S do
if x < y
then
let S = Set{}
in S := S->including(x);
P := P->including(S)
end
else
P := P->including(Set{})
end
end;
P := P->including(P)
end;
P := P->flatten
end;
S := S->including(P)
end;
S := S->flatten